
Using Large Language Models to Generate IAB Categories for Content
Introduction
The deprecation of third-party cookies has been postponed once again, giving AdTech companies more time to develop alternatives for delivering highly targeted ads while remaining compliant with new regulations. We believe that publishers may take advantage of this delay by selling their ad audiences at a higher value while protecting user privacy, a process made possible by the IAB’s Seller Defined Audience (SDA) specification introduced in 2022. Now, in 2024, with the advent of large language models (LLMs), we see how these models can reduce the effort required for publishers to define their audiences by providing an automated “understanding” of the content consumed by users. Our Solutions Architecture team has built a proof of concept (PoC) to demonstrate the effectiveness of this approach.
For reference, the SDA, as defined by the IAB, allows publishers to segment their own audience and send context signals—such as categories from the IAB Content Taxonomy and segments from the IAB Audience Taxonomy—to buyers, without transmitting any user identifiers. Previously, to sell such data at a higher price, publishers had to integrate with DMPs to crawl their content and eventually deliver the data to buyers. There are two problems with such an approach. One is that this put the timing at the mercy of the DMP, which could lead to delays in classifying content. A bigger problem is that it sacrificed some of the intrinsic value of publishers’ content and allowed it to be aggregated and indexed by DMPs and used for the benefit of others.
The SDA specification simplifies the delivery of audience and context data directly, addressing privacy concerns. For example, publishers who know demographic details about their audiences based on registration can easily include age groups, countries, and many other segments into a standard prebid.js ad context. However, gaining deeper insights into user intent requires more extensive analysis of the consumed content to capture real-time intent and drive product advertisement conversions. We believe that this task is now more manageable with the help of LLMs.
The problem we aim to solve is how to map the content that users are reading to IAB-taxonomy interests and segments, allowing us to send these signals and make ad traffic more valuable for buyers. We built a quick solution prototype, based on the OpenAI LLM, that performs the following process:
-
Takes a web content link
-
Tokenizes the content using the LLM
-
Searches against the IAB taxonomy, which is pre-stored in vector format
-
Returns the matching taxonomy segment or content category
Why an LLM? Because it offers higher precision than keyword extraction methods, as it takes into account the semantics of an article.
We envision the full solution as a lightweight JavaScript or CMS module that would process every piece of published content, map it to the IAB taxonomy, store it as metadata, and use it as context for ad integrations.
Details about the prototype
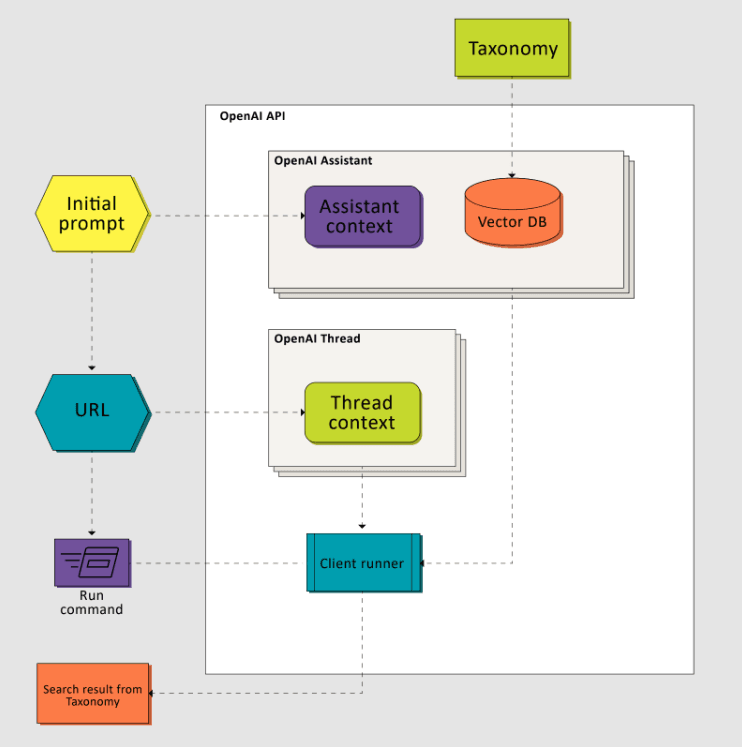
To integrate the LLM with our own context, we used the OpenAI API to create a custom assistant. During the initialization process, we defined the context with an initial prompt and set up storage with content categories as our internal knowledge base. Once it is configured, we can create threads and interact with this custom assistant. The output is a JSON object from the file we used to train the assistant.
While this solution involves some prompt engineering, it requires more than just that. If you simply ask OpenAI to map an article to a taxonomy—even if you include a portion of the taxonomy in the prompt due to size limitations—it may produce inaccurate results, potentially pulling information from the internet or generating irrelevant content. Instead, we instruct the model to “search” for the appropriate category within our preconfigured storage of categories (in JSON documents) based on the content’s semantics.
Result examples
We found Articles Factory to be very content diverse for our purposes. Here is the table with sample results. With a simple eyeball review, you can see there are no hallucinations—it just works.
| Article | Run result |
|---|---|
| Article 1 | """Unique ID""": ""165"", """Parent""": ""163"", """Name""": ""Wedding"", """Tier 1""": ""Personal Celebrations & Life Events"", """Tier 2""": ""Wedding"", """Tier 3""": """", """Tier 4""": """" |
| Article 2 | """Unique ID""": ""96"", """Parent""": ""90"", """Name""": ""Food Industry"", """Tier 1""": ""Business and Finance"", """Tier 2""": ""Industries"", """Tier 3""": ""Food Industry"", """Tier 4""": """" |
| Article 3 | """Unique ID""": ""616"", """Parent""": ""599"", """Name""": ""Data Storage and Warehousing"", """Tier 1""": ""Technology & Computing"", """Tier 2""": ""Computing"", """Tier 3""": ""Data Storage and Warehousing"", """Tier 4""": """" |
| Article 4 | """Unique ID""": ""492"", """Parent""": ""483"", """Name""": ""Cycling"", """Tier 1""": ""Sports"", """Tier 2""": ""Cycling"", """Tier 3""": """", """Tier 4""": """" |
| Article 5 | """Unique ID""": ""658"", """Parent""": ""655"", """Name""": ""Australia and Oceania Travel"", """Tier 1""": ""Travel"", """Tier 2""": ""Travel Locations"", """Tier 3""": ""Australia and Oceania Travel"", """Tier 4""": """" |
Potential for other content types
Our PoC works exceptionally well with textual content, but it becomes even more intriguing when you consider other content types. Generative models can easily extract meaning from videos, podcasts, and images, which opens up even more valuable applications for publishers. Although processing these types of content may be slightly more expensive than the relatively affordable API calls for text articles, it could be worth the investment. For instance, the GPT-4o-mini model requires 17,000 tokens per article, costing $2.55 per 1,000 articles, with an option to receive a 50% discount for accepting a 24-hour delay in responses.
Authors: Eugene Wechsler, Dmitry Maranik
Share:
Got a project?
Harness the power of your data with the help of our tailored data-centric expertise.
Contact us